1分以内にaws lambdaでファイルをマージする方法
AWSのLambdaで S3にある複数のファイルを一つにマージして別のS3に置く、ただし1分以内で
こんな仕組みを実現するために考えたことを共有しようと思います。
このブログを読むと分かること
- 1分以内に4000ファイルを1つのファイルにまとめる方法
前提条件
- S3がファイルを格納するサービスなんだなぁというのがふんわりわかっていること
- Lambdaが関数を実行するサービスなんだなぁというのがふんわりわかっていること
- unixベースのシェルコマンドを実行するとどんな感じになるか少しは分かること
- pythonのコードがある程度なら読めること
イメージ
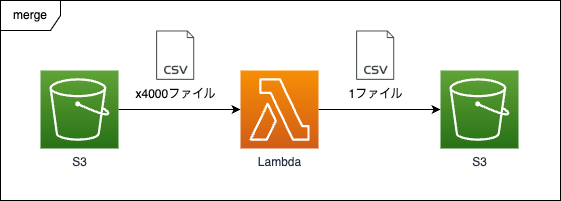
S3には大量のファイルが送られており、1分あたり最大で4000ファイルが格納されるのを想定しています。
このファイルは1ファイルあたり2kbくらいのサイズのものです。
こちらのファイルは後続で別の処理をするのに使うのですが、一つずつ読み込んで処理するのに時間がかかるため、ひとまとめにする処理を挟むことになりました。
こちらの4000ファイルを1分以内に1ファイルに一まとめにし、そのファイルをS3にアップロードする必要があります。
どうすればよいでしょうか?
対応
次の3つの視点で考えていきます。
- S3から4000ファイルをダウンロードする
- ダウンロードした4000ファイルを一つにまとめる
- まとめた一つのファイルをS3にアップロードする
S3から4000ファイルをダウンロードする
pythonにはboto3というAWSのコマンドを扱えるライブラリがあるのですが、大量のファイルを短時間で取得するコマンドが見つからなかったので、aws-cliをlambda上で扱えるようにして、s3 syncコマンドでダウンロードするというアプローチでダウンロードを行いたいと思います。
aws-cliをlambda上で扱えるようにする方法は下記を参考に実施しました。
こちらの設定がうまくできると、/opt/awsからアクセスできるようになるので、python上でCLIコマンドを実行できるsubprocess.run()を使ってダウンロードしましょう。
subprocess.run(f'/opt/aws s3 sync s3://cacapon-sandbox-s3/test /tmp/input/{output_dir}', shell=True)
上記を実行すると、s3 sync で cacapon-sandbox-s3/test オブジェクト下のファイルを全てダウンロードし、/tmp/input/{output_dir} 直下にダウンロードしたファイルを置くことができます。
最後のにくっついているshell=Trueは渡した文字列がシェルコマンドですよと認識してもらうための設定です。
これを実行すると、1GBメモリで37秒, 2GBで19秒前後でダウンロードされます。
ダウンロードした4000ファイルを一つにまとめる
今回はcatコマンドで実施しました。python上で行う場合は同じくsubprocess.run()です。
catコマンドは指定したファイルの中身を表示するコマンドですが、ワイルドカード指定すると対象のファイルを全部くっつけた状態で出力されます。
subprocess.run(f'cat /tmp/input/{output_dir}/* > /tmp/output/merge_yyyymmdd_hhmmssfff.csv', shell=True)
こちらは自前の環境でコマンドを実行したところ、0.091秒でした
まとめた一つのファイルをS3にアップロードする
まとめたファイルのアップロードはダウンロードと同じくs3 syncを使用しました。
s3 sync はローカルファイル S3のアップロード先 と指定するとファイル丸ごとアップロードできるようになります。
subprocess.run(f'/opt/aws s3 sync /tmp/output/ s3://cacapon-sandbox-s3/output/', shell=True)
こちらで実行すると1GBで2.5秒、2GBで1.5秒ほどで実行できました。
まとめ
最終的なコードは以下のようになりました。
import uuid import subprocess import logging import boto3 logger = logging.getLogger() logger.setLevel(logging.INFO) def main(): output_dir = str(uuid.uuid4()) # download subprocess.run(f'/opt/aws s3 sync s3://cacapon-sandbox-s3/test /tmp/input/{output_dir}', shell=True) # merge subprocess.run('mkdir /tmp/output', shell=True) subprocess.run(f'cat /tmp/input/{output_dir}/* > /tmp/output/merge_yyyymmdd_hhmmssfff.csv', shell=True) # upload logger.info("upload start") subprocess.run(f'/opt/aws s3 sync /tmp/output/ s3://cacapon-sandbox-s3/output/', shell=True) logger.info("upload end") # 片付け subprocess.run('rm -rf /tmp/input/{output_dir}/', shell=True) # 確認 subprocess.run(f'ls /tmp/input/{output_dir}/', shell=True) subprocess.run('stat /tmp/output/merge_yyyymmdd_hhmmssfff.csv', shell=True) def lambda_handler(event, context): main()
前述のようにlambdaのメモリ設定で時間は異なりますが、1GBでおおよそ37秒、2GBで19秒前後で処理を完了できますので、無事1分以内に収まりました。
今回は結果だけ書いたのでここに至るまでの経緯は省いてしまったのですが、for文の繰り返しだと間に合わない、並列処理だとpythonやlambdaの制約でうまくいかなかったりと苦戦した部分も多々ありました。その話はいずれ別にお話しできればと思います。
本日のブログはここまで、またお会いしましょう。